
MOBIDEM: MOBile IDEntity for the Masses (FUI 21)
2016-2019 : The object of project MOBIDEM is to realize an electronic platform with an advanced electronic signature capacity for an electronic document provided by a third party, which is easy to use and low-cost. The task of the L3i is to develop a biometric authentification system based on face recogntion:
- Collabration labotories: L3i, AriadNext, Oodrive, Oberthur TECHNOLOGIES
- with Jean-Christophe Burie, Joseph Chazalon, Muhammad Muzzamil LUQMAN, Muriel Visani, Ahmad Montaser Awal
Reasearch methods: The challenge of face recognition is to learn a representation being robust to the variation of face pose, gesture, occulussion and illumination in the wild scenarios. It is also required to recognize the heterogeneous faces presented in the different modalities (e.g., natural faces v.s. caricatures). Metric learning, Multitask learning and Multimodal learning are used to develop the face recognition using large-scale datasets and the related problems such as facial expression recognition and face detection.
- Simple Triplet Loss Based on Intra/Inter-class Metric Learning for Face Verification:[ICCVW2017][code]
Key words: Metric learning, class-wise triplet loss, CNNs, face recognition
In this work, we propose a simple class-wise triplet loss based on the intra/inter-class distance metric learning which can largely reduce the number of the possible triplets to be learned. However the simplification of the classic triplet loss function has not degraded the performance of the proposed approach. The experimental evaluations and the visualization of the distribution of the learned features has also shown the effectiveness of the proposed method comparing to the other state-of-the-art loss function such as cross-entropy loss and centerloss.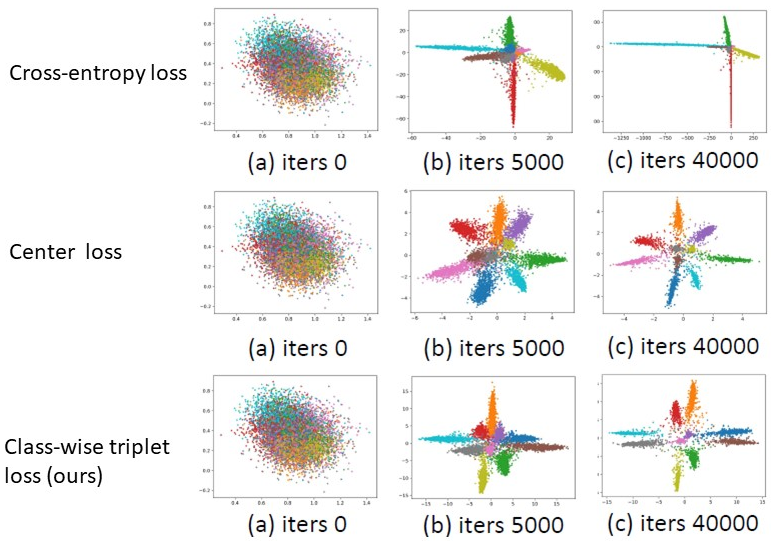
Key words: Multi-task learning, Dynamic task weights, CNNs, face recognition, facial expression recognition
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this work we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate this multi-task learning with dynamic weights boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.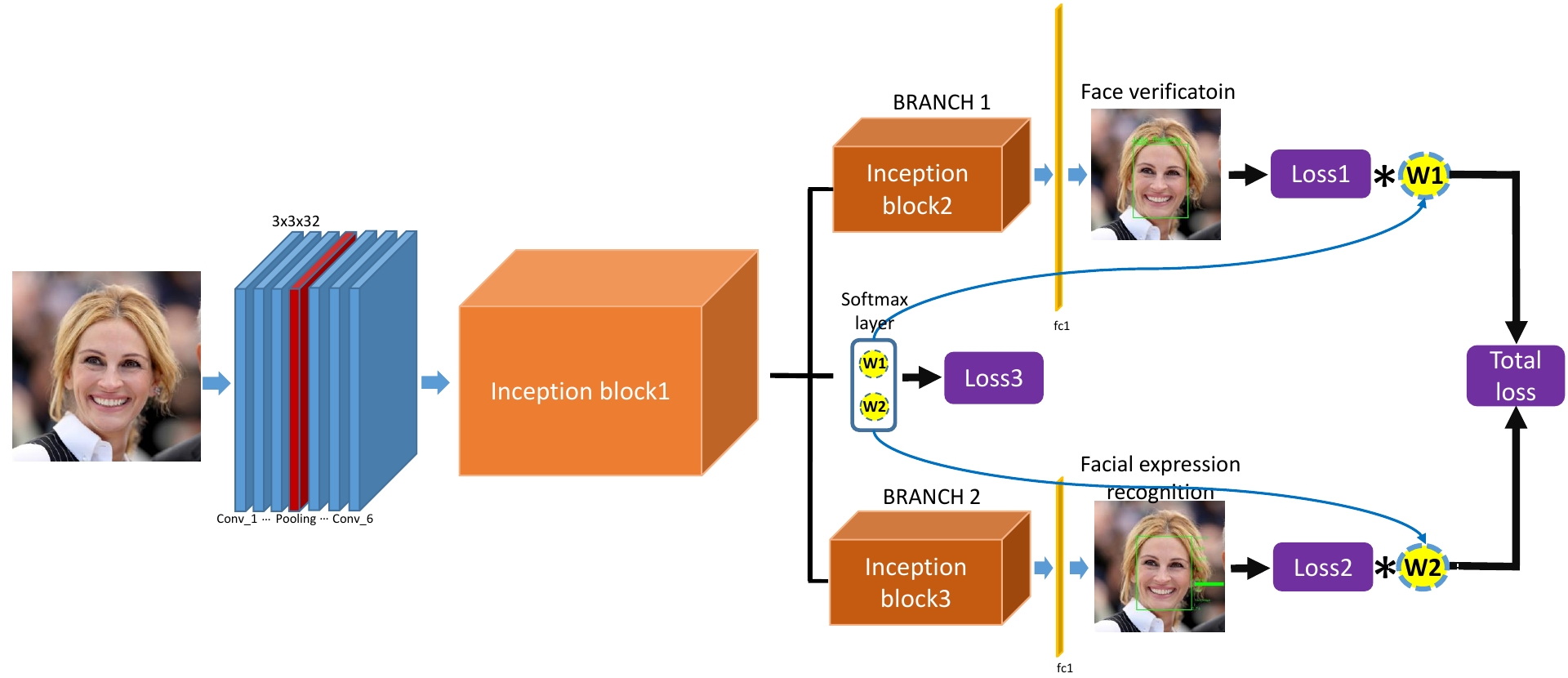
Key words: Cross-modal face recognition, caricature face recognition, dynamic multi-task learning, CNNs
Face recognition of realistic visual images (e.g., photos) has been well studied and made significant progress in the recent decade. However, face recognition between realistic visual images/photos and caricatures is still a challenging problem. Unlike the photos, the different artistic styles of caricatures introduce extreme non-rigid distortions of caricatures. The great representational gap between the different modalities of photos and caricatures is a big challenge for photo-caricature face recognition. In this work, we propose to conduct cross-modal photo-caricature face recognition via multi-task learning, which can learn the features of different modalities with different tasks. The experimental results demonstrate the effectiveness of the proposed method for cross-modal photo-caricature face recognition.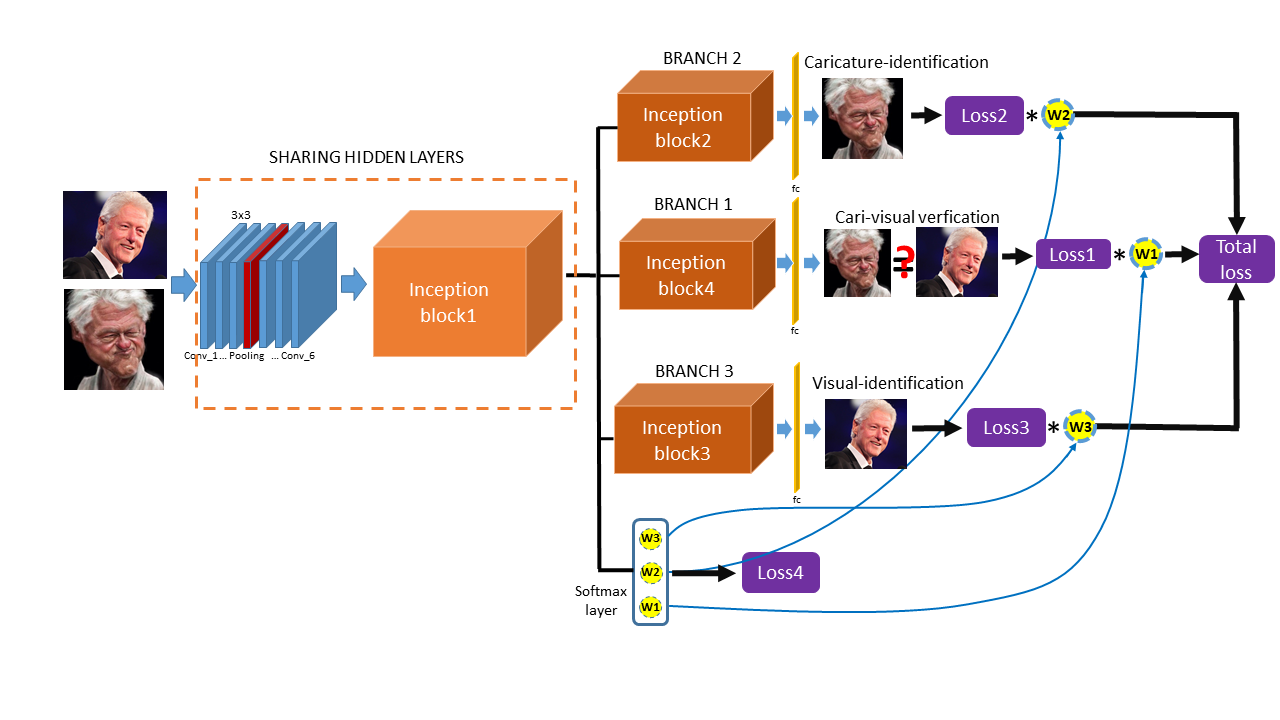
Application Demo:
- Multi-task learning for face recognition and facial expression recognition: (Python, Tensorflow, OpenCV, GPUs/TitanX for training, CPU for Infering/14fps)